It was one of those gray SF days. Pandemic era. Everything was closed. I had been in the Bay Area for a bit, but I hadn’t really left the city much. Still very much a San Francisco rookie.
One day I decided to take the first BART train to “anywhere” and see what happened. It was me, my helmet, and a 1972 blue Schwinn. That bike was the first and is still one of the most important things I’ve ever bought here. Civic Center Station was empty and weirdly echoey. Five minutes later I was sitting on a Yellow Line train headed to a place called Antioch. Never heard of it before. Felt like a good start.
Then the journey began.
Arrived in Oakland.
Still gray and probably cold.
Let’s keep going.
Then something changed
The train went through a short tunnel and suddenly everything was different.
Bright blue sky.
Warm air.
Green everywhere.
It felt like I had crossed a border I didn’t know was there. Like stepping into a different world without customs. Turns out that was Orinda. I had just discovered the magic wall that is the Oakland Berkeley hills. The same hills that trap SF fog like an overachieving gatekeeper.
I stepped off the train in awe. The sun hit different. The neighborhoods hit different. Rolling hills, bike paths, tree-lined creeks, a place that felt like it wasn’t trying to be cool and somehow already was. Like a scene from Stand by Me. I explored Orinda, Lafayette, Danville and eventually Walnut Creek. By the time I rode back home, I was obsessed. I told my roommates we should move. A few weeks later, we did.



That was the start of all this.
I’m writing this now from Walnut Creek, after spending the day walking downtown, riding the free shuttle that still feels like a small miracle. Free public transportation felt like something out of science fiction, especially coming from Brazil where the answer to that idea was always a loud no from anyone in a suit.
Contra Costa County figured out a way. County Connection, local taxes, partnerships and maybe some leftover 70s optimism. It’s not perfect but it works, and it still blows my mind. This whole thing allowed us to not have a car and rely on bike paths and public transportation.
I’ve met incredible people here. Folks from Sustainable Walnut Creek, SCOCO, city staff, retired scientists, former mayors, teenage activists. I somehow ended up organizing Earth Month events and even a climate march. Things I never pictured myself doing. Turns out if you spend enough time outside and say yes to enough random emails, unexpected things happen. And you meet people you actually want to see again.
Making friends as an adult isn’t easy. Making friends while cycling and volunteering is almost like cheating. You keep bumping into the same faces. You see someone having a picnic and it turns into a conversation. Then another. That’s how it starts.
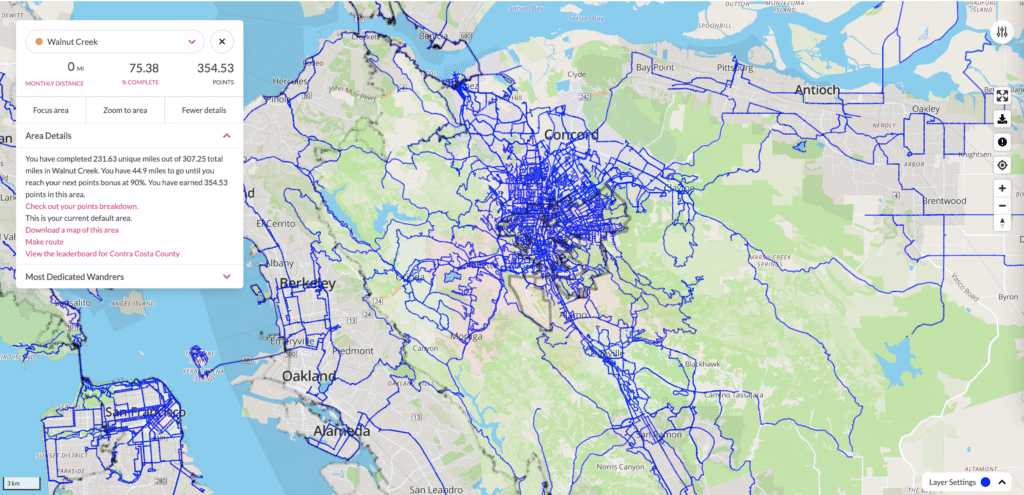
I became so obsessed with Walnut Creek that I decided to bike/run every single street. No idea why. I’m at 75 percent, around 231 miles out of 307 and I’ve covered around 20 percent of Contra Costa County. Even gated communities couldn’t stop me. Sometimes I would wait for someone to open the gate and sprint in like a raccoon. If you saw complaints about a confused cyclist on Nextdoor, that was probably me.





Then there’s Mount Diablo
My first time climbing it took me seven hours. Same old Schwinn. I had a crisis halfway up. I promised myself I would never do that again. But when a mountain stares you in the face every morning, you eventually give in. I’ve climbed it many times since then (New bike though). Once I even saw snow falling at the summit. It was unreal. I once challenged myself to climb it seven times in one day. Never made it past one and a half.
Walnut Creek is framed by hills and a mountain that keeps refusing to stay in the background. It’s a place that doesn’t care if you quit halfway. It waits. It just keeps being itself.






Bookworm life
The libraries here are wild. Some are over 100 years old, started by women’s clubs who also organized community festivals and clean-ups. Many of the city council members over the decades have been women. That kind of energy sticks to a place. I live close to the Pleasant Hill Library now, which might be the best place on earth on Saturday mornings, especially after a coffee from Rooted Coffee in Poet’s Corner.
Once Leandra caught me sleeping in the library, I officially became one of those elderly people who nap there.
I’ve spent years trying to understand what exactly this city does to me. Why it keeps pulling me in. Maybe it’s the weather. Maybe it’s the bike paths. Maybe it’s the fact that people bring up things like graywater systems in casual conversation.
Maybe it’s something else. Maybe it’s just the feeling that a place can start as an accident and somehow end up as home.





Whatever it is, I’m still here. And it still feels right.
Lately though, there’s been a quiet itch. Not to leave for good, but to look around. To see if there’s another corner of this country that feels this charged, this accidental and somehow perfect.
I don’t know what I’ll find. I don’t know if I’ll find anything. But I do know that no matter where I go, a part of me will always be here. Somewhere between the library and the mountain and the street I haven’t ridden yet.
And there are the people. The ones I’ve shared bike rides and late-night strategy meetings and awkward first hellos with. Leaving means risking the kind of drift that happens when life changes shape. I’m not ready to lose that. I hope geography doesn’t get the final say on who stays close.