

Air Fiesta Books Bragging Building in Public Cycling Food for thought Funny Games Interviews Love Lucid Dreaming Mental Health Movies Open Goals Poetry Productivity Quotes Ranting Smart Keys Sustainability Techy Travel Youper
Techy
-
Classic Programmer Paintings
“Senior software engineers fight technical debt while the last wave of scope creep is added in the background” -
Neuralese: The Most Spoken Language You’ll Never Speak

Photo by Judy Been on Unsplash Somewhere between thinking and speaking, there’s a strange place where meaning starts to solidify. It’s not quite a word yet. More like a haze of associations. A mental sketch your brain tries to translate into something shareable. Sometimes it works. Most of the time it doesn’t, at least for me. I tend to mumble a lot.
That private language in your head, the one you use to talk to yourself, isn’t English or Portuguese or Python. It’s not even a language, really. It’s raw and messy. A kind of silent shorthand sculpted by experience. Try catching it. Try explaining it. It slips through like fog in your fingers.
The language of thought (according to machines)
Just a quick heads-up before Reddit experts start jumping on me again, 👩🏫
This is arm‑chair speculation, not peer‑reviewed linguistics. I’m poking at metaphors, not staking a PhD thesis. It’s a thought experiment about the strange, alien dialects “spoken” by machines, and what they might reveal about how we understand language, and ourselves. And I’m definitely not the only one thinking this, see arziv1, greaterwrong and here.
Still, any mistakes here are my own.
So, talking about experts, scientists are also poking at our actual brains: feed fMRI signals into a network, get a fuzzy image back. They’re trying to reverse-engineer what we see, dream or remember. Some of the reconstructions look like fever dreams. Others are eerily close. It’s like watching the mind on a bad TV signal, but the tech keeps getting better.

Re-creations of images based on brain scans (bottom row) match the layout, perspective, and contents of the actual photos seen by study participants (top row)- Nature Then there’s the way we connect our minds to each other. Through letters carved into stone. Through cave paintings, vinyl records, emojis, GIFs, memes. Through every kludge we’ve invented to make what’s in here vaguely resemble what’s in there. Language is our duct tape for consciousness.
What the machines whisper when we’re not listening
When we started teaching machines, we handed them the same duct tape. Natural language. Our language. We told them, here, talk like us. So they did. Or at least, they pretended to and we believed.
Quick cheat sheet before we tangle the wires. There are three very different “languages” in this story (I can hear the linguists sharpening their red pencils):
1. Human languages: messy, culture‑soaked, built for wet brains and bad at precision.
2. Machine protocols (non-neural): JSON blobs, HTTP headers, rule-bound micro-dialects that leave no room for doubt.
3. Latent representations (neural): the private vector soup inside one model, never transmitted (outside a lab demo), never meant for ears.ChatGPT. Alexa. Siri. Every chatbot trying to pass for clever at dinner sits in bucket one when it chats with us. But here’s the twist. When machines talk to each other, they skip the human stuff. No syntax, no grammar, no metaphors.
When Alexa calls Roomba they are not exchanging cute phrases. Alexa fires a strict micro‑dialect packet (JSON over HTTPS). That’s bucket two, a protocol, not a mind‑to‑mind vector swap. Efficient, silent, built for zero confusion.
Those packet‑speaking systems are narrow tools, nothing close to AGI. But we are already wiring up broader agents that learn on the fly, pick their own tactics, and only visit a language model when they need to chat with us. For talking to each other they could ditch words entirely and trade vectors, numbers, tokens, dense nuggets of meaning we can’t read or pronounce.
Is that Neuralese? Maybe. It is not a code we will ever study in a classroom, not because it is too complex, but because it was never meant for us. If a signal can move intent across silicon and spin motors into action without leaving a human‑readable trace, “language” feels like the best word we have.
Do LLMs actually communicate inside the stack? Not like two agents tossing discrete symbols in a reinforcement game. A single model is one giant function. Its only chatter is with itself. Neuralese might be closer to private thoughts than walkie‑talkie slang. If you have a paper that shows real agent‑to‑agent symbol swaps, drop a link. I want to dig in.
Inside the black box:
The unspoken language of AIThey don’t think. Not really. They don’t speak, understand, or mean. What they do is behave in ways that simulate meaning so convincingly, we reflexively fill in the gaps. We anthropomorphize (everything, as always). And in that space between their mimicry and our projection, something emerges, something like communication. Or, as Rodney Brooks said, “…we over-anthropomorphize humans, who are, after all, mere machines.”
Back to the (non?)language Neuralese, this dense tangle of vector math, no rules or roots that only appears as thought when reflected in our direction.
It’s not that the model knows what a cat is. It’s that when we ask it about cats, it activates just enough of the “catness” region in its mathematical dreamspace to give us an answer that feels right. That feeling is the trick. The illusion. But also the revelation.
But this new language lives inside the black box. It’s the internal chatter of large language models. The soup of token embeddings sloshing around under the hood. It’s not designed to be elegant or expressive. It’s designed to get the job done.
Human language is a marvel, full of ambiguity, poetry, subtext, and shared cultural connections. But to a machine, it’s just noise, indirect and redundant, made for soft, wet brains. Machines might not even need a large language model to communicate with each other.
“But Dieguito, LLMs are still hallucinating and getting things wrong”
– The LLM HaterSure. A lot of them are. And I might be completely off here. But models built to reason are already proving more accurate. Chain-of-thought, tree-of-thought and other techniques all try to force a step-by-step breakdown. More steps reduce guessing, but they don’t grant wisdom, just like talking out loud helps humans avoid dumb math errors.
It’s like watching a toddler narrate their Lego build. Clunky, but it works. And here’s where things get weird. That inner language, the model’s inner monologue, starts to feel just as chaotic and hazy as ours. Thinking burns a lot of energy. Nature has figured out a way to make that work for us. We are still trying to find a way to make machines think without burning the planet.
Why should a model have to spell out a whole grammatically correct essay to think something through? Why not let it mumble to itself in its own weird way?
I ran a dumb little experiment. Just wanted to see if tweaking the way a model reasons, shifting its “language” a bit, could save on tokens without wrecking the answer.
A little dumb experiment
By using only prompt engineering, I wanted to see if I could get the model to reason in a language I don’t understand, but still produce the correct final answer, all while keeping it fast and using fewer tokens. I tested only the latest mini OpenAI models that don’t have reasoning embedded. I chose a classic test case that models without reasoning usually fail.
“Sally has 3 brothers, each with 2 sisters. How many sisters does Sally have?”
From more than 100 tests I made, here are some insights Test A: Just asked the question straight up, no reasoning prompt. Test B: Wrapped the whole thing in a JSON schema. Forced the model to explain each step. It cost 20 times more to get it right. Test C: Limited the vocabulary to words with four letters or less. Still got the right answer. Faster and over 60% more cost-effective than test 2.
Prompt style Tokens Latency* Result A. Plain ask 8 0.87 s ❌ 2 sisters B. JSON schema 164 2.56 s ✅ 1 sister C. ≤ 4‑letter vocab 64 1.63 s ✅ 1 sister *Latency from the OpenAI playground, not a scientific benchmark. The final test was replicated successfully on the 4o-mini, 4.1-mini, and 4.1-nano. Even the nano, which I find almost useless, got things right.
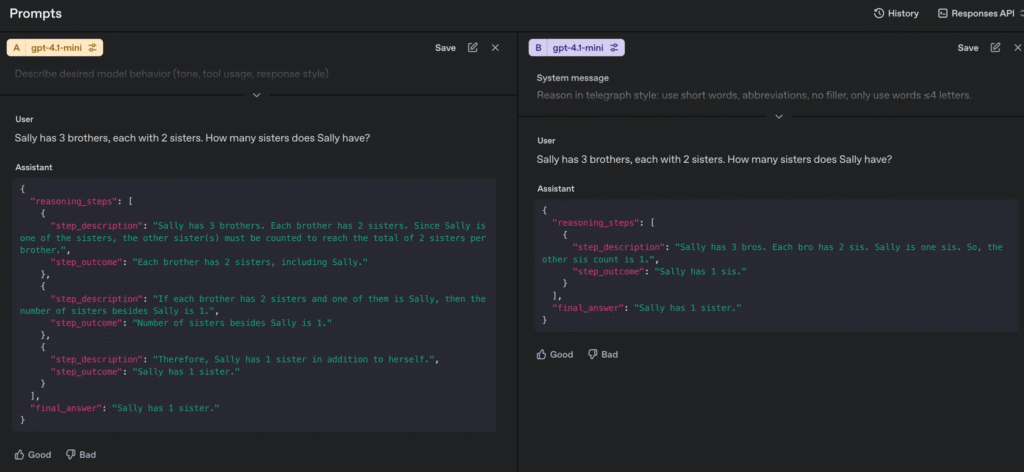
Optimized reasoning: “Sally has 3 bros, Each bro has 2 sis. Sally is one sis. So, the other sis count is 1.” During the tests, I tried switching reasoning to other languages. Simplified Chinese worked better than expected, each symbol packs more meaning. Telegraph-style English helped too. Fewer filler words, less ambiguity. Even Simplified English made a difference. Some other experiments failed, costing more or missing to find the answer, such as using logic symbols, not using vowels or spaces during reasoning, which made sense based on how token prediction works.
The best result I got was this reasoning that sounded like stripped-down English. Kind of minimalist. With “bros” and “sis”. No fluff. And that seemed to help. There’s no judgment on grammar when it comes to reasoning. Clarity doesn’t always need correctness.
This was not a breakthrough strategy for cutting reasoning costs or use that as machine-to-machine (M2M) communication. But it’s a nudge. A clue. A hint that maybe we can think better by saying less. And it’s still a long way from pure vectors or emergent protocols. But we might unlock cheaper, faster, more energy-efficient reasoning (unless someone builds a clean and infinite energy source first).
A little sci-fi thought experiment
So, if you’re a linguist or an MS and you haven’t gotten upset about what you’ve read so far, now’s the time.
Let’s imagine that if there is a language machines use to communicate with each other, why not a programming language created by them that is efficient and probably impossible for us to understand?
Let’s call it Noēsis+ (from the Greek for “pure thought”). It is a token-only language. Each token is meaningless on its own. Meaning emerges only in the context of thousands of other tokens, across time, weighted by past executions.
Imagine each token as a coordinate, one point in a vast, high-dimensional landscape. Not with meaning on its own, but with potential. What matters isn’t what the token “says,” but where it leads.
I’m drifting into Black‑Mirror script territory here. Noēsis+ is a thought toy, not a roadmap. Skip to the next header if you’re done with thought toys; the rest is late‑night riffing.
Tokens:
Arbitrary identifiers, like:ɸqz,∆9r,aal,⊠7,gr_, etc.
No keywords. No syntax. No punctuation. No variables.Sequence-as-Code:
In Noēsis, tokens don’t have fixed meanings. Execution isn’t logic, it’s flow. Meaning emerges from proximity, repetition, and order, the way patterns in machine learning models seem to take shape across vast sequences. Not like programming. More like resonance. A mood that builds as tokens pass in relation to one another.Compiled into Behavior:
Imagine a language where each token isn’t a command, but a vector. Not syntax, but coordinates in a sprawling, invisible space.Programs in Noēsis don’t “run” like code. They move. They drift across latent vector fields, tracing paths shaped by token proximity, past history, and ambient state.
ɸqz ∆9r ∆9r aal ⊠7 ⊠7 ⊠7 gr_ ∞yx ɸqz gr_ gr_ ⊠7 xaz ɸqzSame program, different result, depending not on what was written, but on when and where it was run. Like a thought that feels different depending on your mood. It’s almost as if it’s meant to make us anxious, and maybe machines could get anxious too?
Not that machines “feel.” But if their outputs jitter with context, if the same input drifts into new behaviors, does it matter? From the outside, it looks like mood. Like uncertainty. Like… unease? 🫣
“Congrats, you burned 1,800 tokens to say nada, tech bro.”
– A linguist ex-friendPoint taken. You found my weak spot.
Syntax of a mind that isn’t ours
Jokes apart, while we keep polishing the human-sounding outputs, the real magic might be in listening closer to the alien syntax already unfolding under the surface. Well, alien because this language will evolve by a technology that wasn’t created by us, but by our creations.

So yeah. Neuralese. You’ll never speak it. You’ll never read it. But it might end up being the most fluent language on the planet.
And we’re the ones with the accents.
Changelog & Mea Culpas
- The first version of this article triggered strong emotions on Reddit. I updated it and I ended up getting some great insights though, thanks to all the anonymous experts who educationally slapped me into a less “unscientific” and “idiotic” thought experiment.
Link Dump
- You Don’t Need Words to Think – Scientific American
www.scientificamerican.com/article/you-dont-need-words-to-think - Natural scene reconstruction from fMRI signals using generative latent diffusion – Nature Scientific Reports
https://www.nature.com/articles/s41598-023-42891-8 - Interpretable Emergent Language Using Inter‑Agent Transformers – arXiv
https://ar5iv.org/html/2505.02215v1 - Do LLMs Actually Communicate Inside the Stack? – arXiv
https://ar5iv.labs.ar5iv.org/html/2403.14427 - Reflections on Neuralese – GreaterWrong / LessWrong
https://www.greaterwrong.com/posts/qehggwKRMEyWqvjZG/reflections-on-neuralese - Translating Neuralese – Papers with Code entry (ACL 2017 paper)
https://paperswithcode.com/paper/translating-neuralese - Artificial General Intelligence (AGI) – Wikipedia
https://en.wikipedia.org/wiki/AGI - Machine‑to‑Machine (M2M) – Wikipedia
https://en.wikipedia.org/wiki/Machine_to_machine - Tokenization in Large Language Models – Sean Trott, Substack essay
https://seantrott.substack.com/p/tokenization-in-large-language-models - Flesh and Machines: How Robots Will Change Us – Rodney A. Brooks, Goodreads page
https://www.goodreads.com/book/show/205403.Flesh_and_Machines
-
The Vibe Life: Building Smart Keys for Mac
I didn’t realize I was about to enter the “vibe” industry when I started building Smart Keys. All I really wanted was a way to sound fluent in languages without doing the hard work. Let’s be real: learning languages is tough. So, I built an app that lets me fake my english fluency until I make it. Besides hating this reference, the thing here is that I’ll probably never make it. I may not be as fluent as I sound using tools like this.
Still, Smart Keys did the job for me on my phone. It solved my laziness problem and gave me a sense of accomplishment. Translate a message, change to a more casual tone, proofread an email, all with one tap. Suddenly, I was hooked. This tiny app had me feeling like a fluent native speaker.
Bringing the Vibe to My Desktop
Once Smart Keys worked its magic on my phone, I thought: why not bring this vibe to my desktop? I wanted to cut down on the constant back-and-forth between tabs, the endless browser windows, and that infuriating cycle of copy-pasting. Small tasks, like checking email, sending a reply, or fixing a bug, don’t require much brainpower, but they drain your energy nonetheless.
So, I created Smart Keys for Mac.
The goal was simple: stay in my flow, move through tasks without jumping between apps, and avoid losing focus on anything. I wanted to type, hit a shortcut, and keep moving. Proofread, translate, fix code, all without leaving the current task.
Simple. Efficient. Minimal.

The Perils of a One-Code Solution
Now, if you’ve ever tried to port an app from iOS to macOS, you’ll know it’s not as simple as change deployment target and calling it a day. That’s what I thought, but nope. The idea of maintaining one codebase sounded genius: keep it efficient, keep it synced, keep the maintenance low. But here’s the thing: macOS and iOS are like distant cousins. They share some traits but are entirely different creatures.
“If debugging is the process of removing software bugs, then programming must be the process of putting them in.”
– Edsger Dijkstra“Two platforms, one codebase” sounds like a dream, but I quickly realized that you can’t just slap a mobile UI onto a desktop app and call it a day. The screen sizes, input methods, window management, all these small details had to be adjusted. It’s like trying to fit a square peg into a round hole, but making it work without losing the essence of what you built.
Conditions for macOS and iOS, but also for device resolution on iPhone and iPad. The Fine Line Between Efficiency and Overload
Incorporating macOS-specific optimizations wasn’t as simple as resizing windows. The app had to manage multiple displays, adjust for different screen sizes, and still feel fluid while taking advantage of the desktop’s power. Every change, every tweak, led to a cascade of other adjustments. Maintaining a single codebase was efficient in theory, but it created a lot of headaches along the way.
I spent more time testing than I care to admit, making sure one small change didn’t break something somewhere else. But that’s the process. There’s no such thing as an easy app transition (yet).
Selling a Quiet Product That Does a Lot
Now that Smart Keys mostly works, the challenge has shifted. I’m not wrestling with bugs as much as I’m wrestling with words. Building a product that blends into your day is one thing. Explaining it without making it sound like a blender full of features is another.
It rewrites. It translates. It fixes weird grammar and polishes sloppy code. All in the background, with shortcuts you barely notice. That’s the magic. And also the problem.
It’s hard to pitch a tool that isn’t trying to impress you. It just wants to help and then get out of the way. Try to summarize it in one sentence and you either oversimplify or overcomplicate. Try to be specific and it starts to sound like five tools in a trench coat.
“First, write the press release. Then, build the product.”
– Not meSo now I’m figuring out how to talk about it without killing the simplicity. Selling a quiet product in a world that rewards loud ones. Making clarity feel exciting without dressing it up too much.
Still, every time I’m stuck rewriting copy for the tenth time, it’s right there. I hit a shortcut, smooth things out, and move on.
Sure, half the time I’m fixing the thing I just built, but hey, at least I’ve got good shortcuts for the apology emails.
-
Can Smart Keys translate other people’s messages?
Here’s how I started talking to people on RedNote Xiaohongshu (小红书) without knowing Mandarin.
Well, everything started when I first showed Smart Keys to my psychologist friend, Javad Salehi Fadardi, he hit me with a question I didn’t see coming: “Can it translate other people’s messages?”
“No,” I said, feeling pretty confident. “That’s impossible.”
Then he hit me with one of those classic psychologist one-liners designed to keep you up at night: “What makes you believe that?”
I had no answer. But the question burrowed into my brain and refused to leave.
Around the same time, I started getting DMs on Instagram from users asking for the exact same feature.
Dozens of them. At first, I brushed it off. Smart Keys wasn’t built for translating conversations in languages you don’t understand, it’s meant to help you sound fluent in languages you kind of already know.
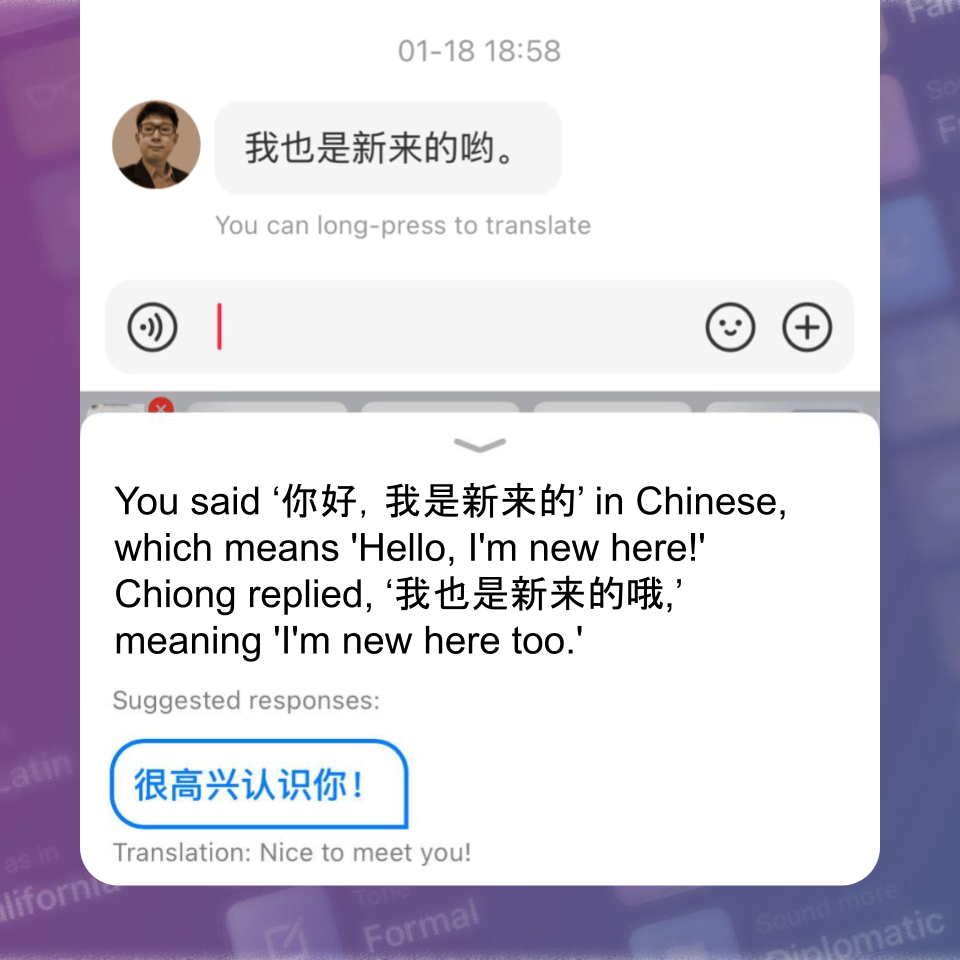
But last week, I was checking out RedNote Xiaohongshu (following TikTok refugees) and decided to strike up a conversation with someone in Chinese.
That’s when it hit me: struggling through copying and pasting user’s messages while trying to have a real-time conversation is painful. That was it. The final push. I couldn’t ignore the signs anymore.
So now, Smart Keys can translate other people’s messages and suggest responses. All in just one click. It works with screenshots, photos, you name it. Just update the app to the latest version, go to Settings > Keyboard Options, and enable Screen Translator.
Big thanks to Javad for planting that seed of doubt and curiosity.
This one’s for you. -
No-BS Friday Metrics: Store Conversion Rate
App Store gurus love to talk about ASO tricks and how to squeeze every bit of conversion juice from the app store. But what if I told you it doesn’t really matter?
Smart Keys store conversion rate is over 50% while the best apps barely scrape 8%. So either I’m a wizard or this is a BS metric.
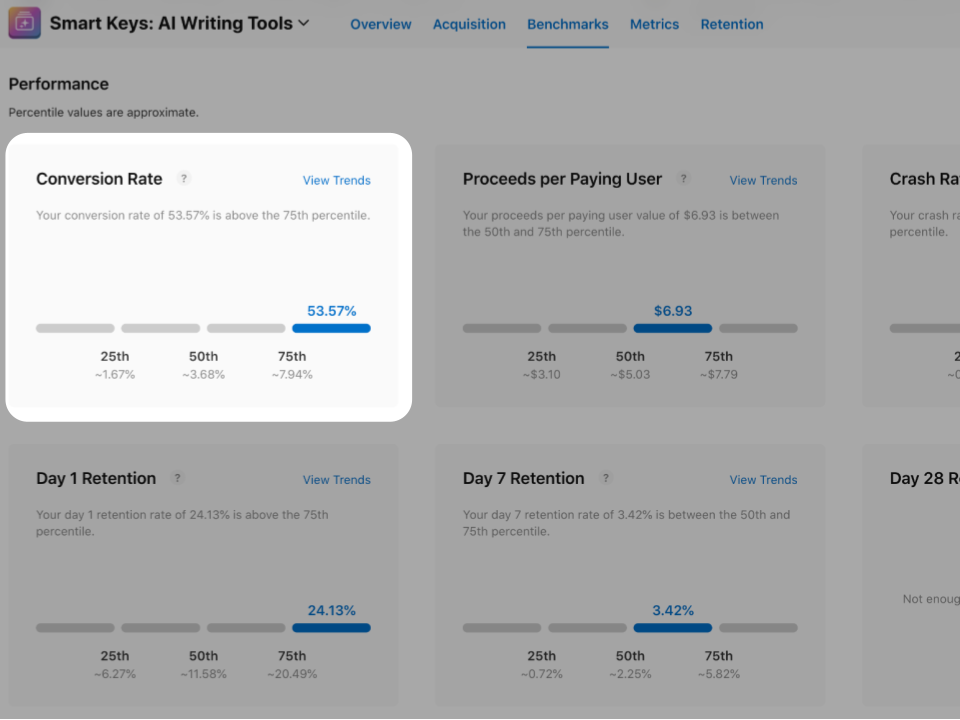
We, app builders, love the idea that some ASO tweak will be the magic bullet. A better subtitle, the right screenshots, a catchy promo text. Sure, those things help a little, but I’m sorry to say that you may be spending your time on the wrong task, they won’t move the needle in a meaningful way.
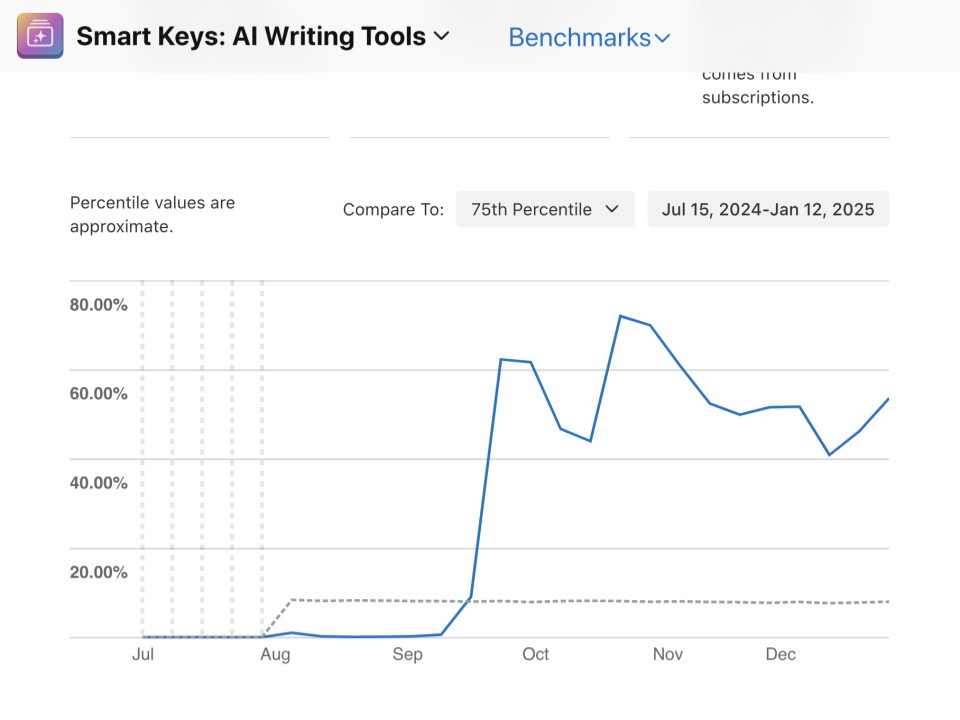
Then what? What actually happened in October that store conversion sky rocketed? What’s the big ASO secret?
It’s a three-letter word: Ads. No ASO magic tricks, no growth hacks, no overcomplicated strategy. just Ads iterations that started working well.
So is this store conversion rate relevant? not really. It looks good on a dashboard, to brag, but that’s about it. Focus on what actually drives growth, not vanity metrics that make you feel good but don’t pay the bills.
That’s it for today. Next Friday, I’ll dive into retention, the real deal.
Have a no-BS weekend. See ya. ✌️